
안녕하세요. 위피/콰트의 데이터 분석을 맡고 있는 신민용입니다.
이번에 소개해드릴 내용은 엔라이즈 데이터 분석가의 A to Z를 말씀드리려고 합니다. 데이터 분석가는 무슨 업무를 하는지, 어떻게 일을하고 있는지에 대해서 소개하겠습니다.
분석가의 업무
ß 결론부터 말씀드리면, 분석가의 업무에는 제약도 제한도 없습니다.
즉, 엔라이즈의 분석가는 데이터와 관련된 모든 의사결정을 서포트할 수 있기 때문에 특정 업무에만 국한하지 않고 업무를 진행할 수 있습니다. 그렇기 때문에 엔라이즈 데이터 분석가는 특정 틀에 갇히지 않은 열린 사고로 업무들을 진행해 나갈 수 있습니다. 여기서는 주요 업무들을 추려서 설명드리겠습니다.
전체적인 업무 카테고리는 6가지로 다음과 같습니다.
- Fraud Detection, Causal inference
- 가설에 대한 사전분석
- 실험설계
- 실험 사후분석
- 제품에 활용될 로직 설계
- Ad-hoc 분석
이처럼 현재 이상치 탐지 및 인과 추론부터 실험 설계와 실험 결과 분석까지 다양한 업무를 진행하고 있습니다.
그렇다면 각 카테고리별 어떤 업무를 진행하고 있는지 사례와 함깨 자세히 설명드리겠습니다.
1. Fraud Detection, Causal inference
Fraud Detection(이상치 탐지)는 다양한 도메인에서 다양한 정의로 사용되고 있습니다. 위피의 경우 이상치 탐지를 결제, 리텐션, 추천 알고리즘에서 주요하게 사용되고 있습니다. 이상치 탐지의 경우 주요 지표들이 하락하거나 증가되었을 때 빠르게 인지하고 대응책을 마련하는데 의의가 있습니다.
일례로 제품 리텐션이 감소했을 때를 가정해보겠습니다. 리텐션이 감소했을 때 그 수치를 빠르게 탐지하지 못했을 때 생길 수 있는 Effect는 큰 폭풍으로 다가올 수 있습니다. 앱 기능이 잘못 배포되어 특정 유저들의 UI가 끊기게 되었을 때 이에 불편함을 느낀 유저들은 결국 이탈하게 될 것인데, 이부분에 대한 인지를 늦게 할 수록 정량적인 손해(Effect)는 기하급수적으로 커질 수 있게 됩니다. 그렇기 때문에 이상치 탐지는 문제가 되는 부분을 빠르게 캐치할 수 있도록 서포트하며, 이에 따라서 빠르게 대응책을 마련하여 발생할 수 있는 Effect를 최소화할 수 있습니다.
현재 Fraud Detection은 구축한 대시보드를 통해서 1차 추적 및 최대한 빠르게 탐지가능하도록 Slack알림으로 최종적으로 트래킹하고 있습니다.

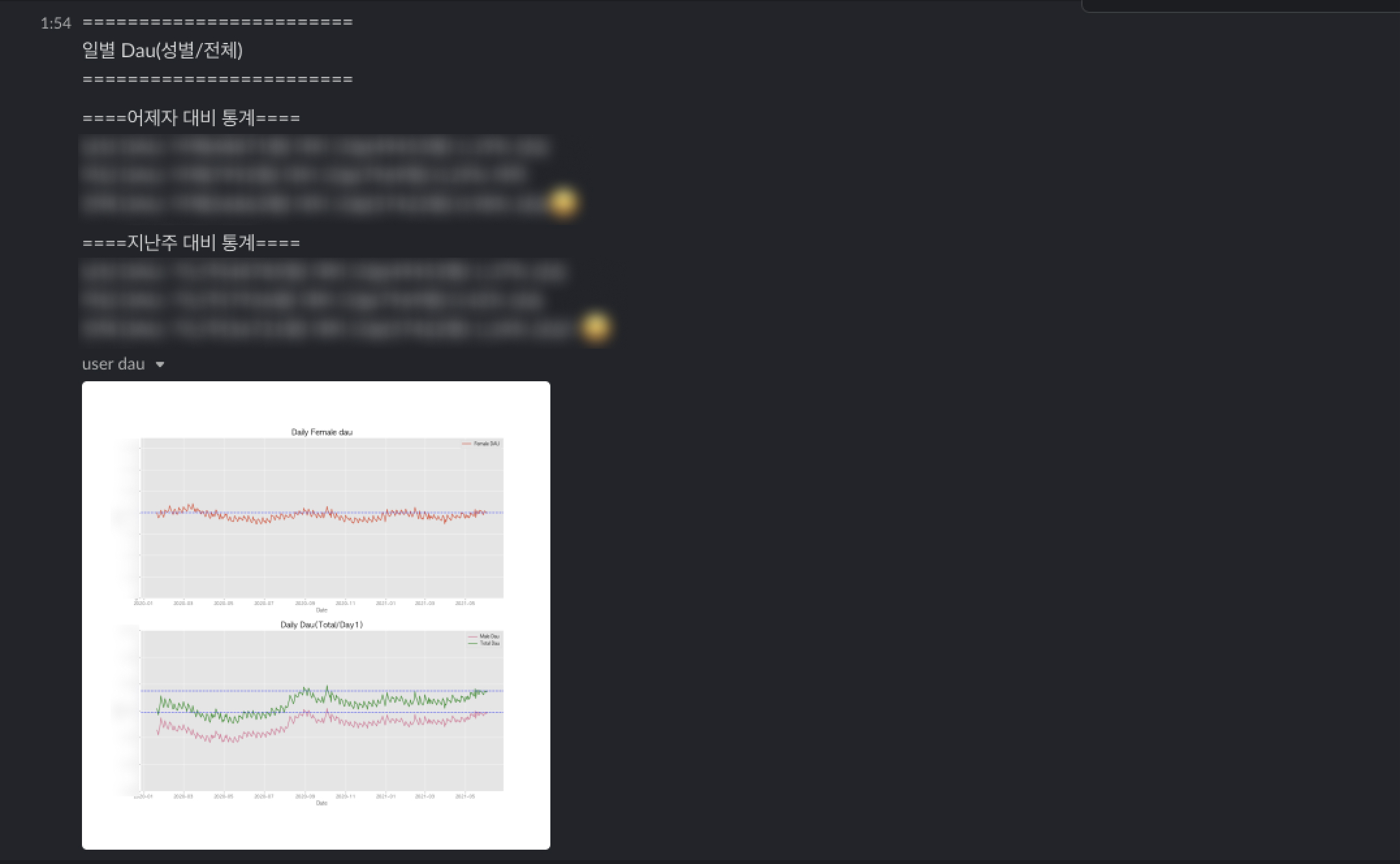
그런데 이상치 탐지는 현황 파악에서 끝날까요? 아닙니다. 이상치가 나왔다는 것은 앱(비즈니스)에 특별한 문제가 발생한 것으로 인지할 수 있기 때문에 원인점을 빠르게 파악하고 분석하는 과정을 거쳐야 합니다.
가령, 유저들의 결제 비율이 감소했을 때 “결제 비율이 최근 이틀에 걸쳐 약 5%p 감소했습니다” 라고 말하는 분석가와 “결제 비율이 최근 이틀사이에 5%p 감소했는데 문제는 추천 알고리즘이 특정 로직에 의해서 잘못 추천되고 있는 것으로 보입니다. 그래서 이 부분을 파악해봐야 할 것 같습니다” 라고 말하는 분석가는 분명히 분석하는 깊이에 차이가 있을 것입니다. 따라서 현재는 문제가 발생한 원인에 대해서 파악하고 그 가설을 검증하기 위한 액션을 제시하는 것까지 진행하고 있습니다.
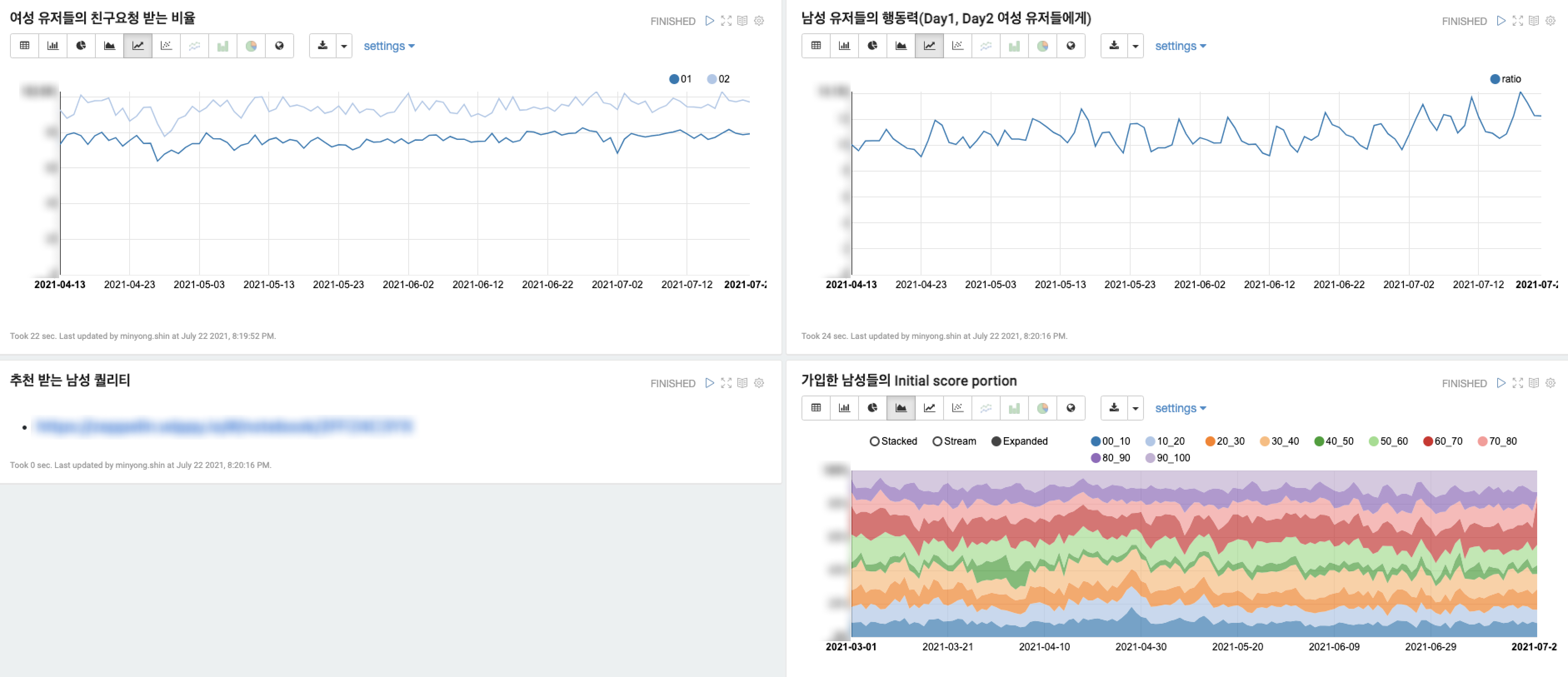
인과추론은 보통 모델을 통해서 진행하지만 제품의 지표들은 특정 인과에 영향성을 많이 받기 때문에 특정 지표 변화에 대한 원인 추론을 빠르게 하기 위해서 모델링보다 Trend metric으로 아래와 같이 분석을 진행하고 있습니다.
2. 가설에 대한 사전분석
가설에 대한 priority analysis는 AB테스트 혹은 전후분석을 진행하기 이전에 가설에 대한 사전 데이터로 분석할 수 있는 최대한을 분석하여 실험의 Effect(ROI)를 확인하고, 좀 더 성공확률을 높이기 위한 작업으로 진행하고 있습니다. 보통 프로세스는(회사마다 다릅니다) 가설 설정 → 가설을 사전적으로 검증하기 위한 분석 → 분석 결과를 통한 가설기반 실험설계의 순서로 진행되는데, 이 부분에서는 가설에 대해서 사전적으로 검증하기 위한 분석에 대해서 설명드리겠습니다.
보통 가설은 실험 이후 파생되는게 일반적이지만 정성적인 요인에 의해서 파생되는 경우도 있습니다. 가령, 유저들이 사용하는 아이템 중 “첫인상“이라는 아이템을 예를 들어보겠습니다. 1차적으로 해당 아이템을 직접 사용해보면서 유저경험을 간접적으로 파악해봅니다. 그 다음 진행중 경험, 결과를 공유 받았을 때 경험을 모두 확인했을 때 결과를 받았을 때 경험에서 세울 수 있는 가설이 있었습니다. 결과를 확인해보니 나에 대해서 관심을 표현한 여자들의 거리가 상당히 먼 유저들도 같이 추천이 되고 있었기 때문에 거리가 먼 사람들을 추천을 받았을 때 심리적인 관심도와 만족도가 저해된다는 느낌을 많이 받게 되었습니다. 따라서 거리가 먼 유저들을 추천 받을수록 행동력이 감소된다 라는 가설을 세우고 사전분석을 진행하게 되었습니다. 거리가 멀수록 행동력이 떨어진다는 가설을 검증하기 위해 거리 Factor를 기준으로 행동력이 어떻게 달라지는지에 대한 Metric을 개발한 뒤 비교를 했을 때 거리가 멀어질수록 Metric이 우하향 하는 추세를 보이는 것을 확인했습니다.
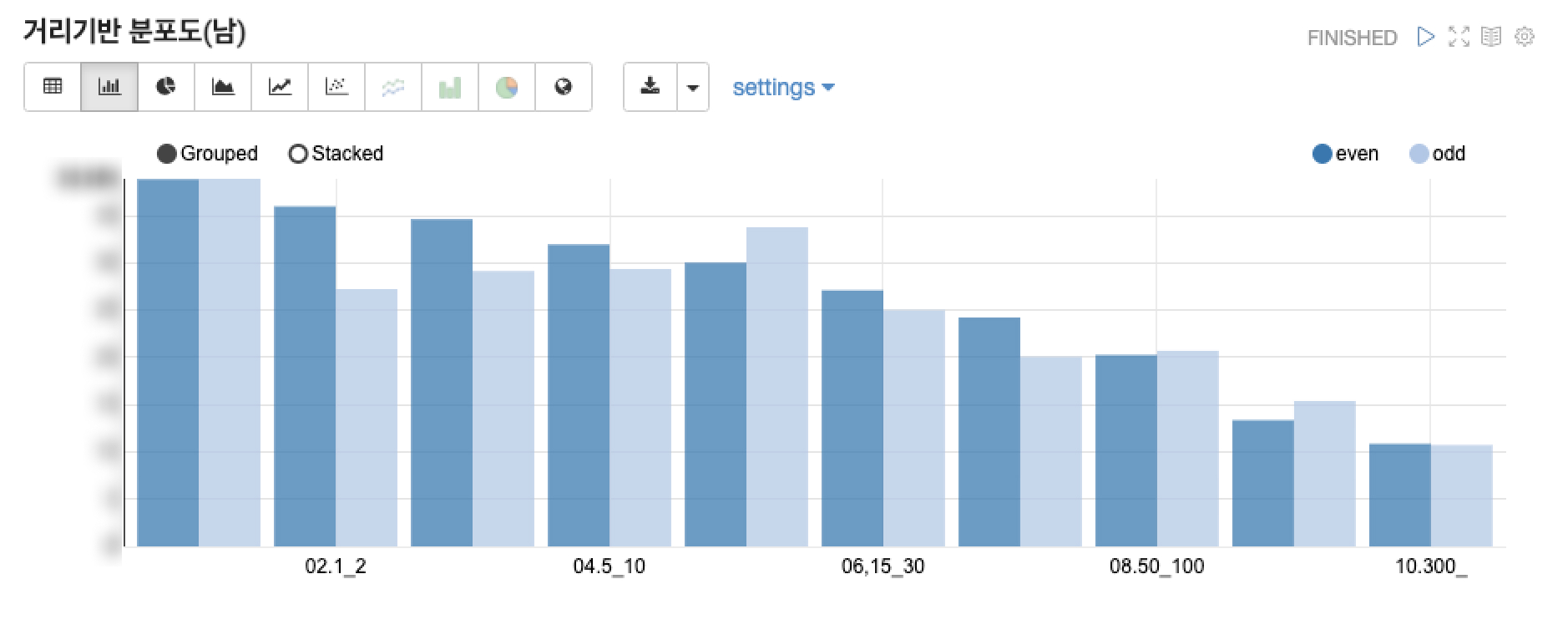
이처럼 사전분석을 통해 사전 Metric을 근거로 실험을 진행했을 때 충분히 성공률이 높아질 수 있도록 만드는 것이 사전분석의 목적이자 실험 설계를 위한 필수 요소임을 말씀드리고 싶었습니다. 그렇다면 분석가는 사전분석에 멈출까요? 그것도 아닙니다. 분석가는 이처럼 사전분석을 통해 도출한 결과를 통해서 실험설계를 진행합니다.
3. 실험설계
실험설계는 제품 성장의 꽃이라고 볼 수 있습니다. 충분한 근거에 기반한 실험설계는 실험의 성공률을 높일 수 있으며 그에 따라서 비즈니스의 성장으로 이어집니다. 그렇다면 실험설계는 어떻게 진행되는지에 대해서 자세히 설명드리겠습니다.
실험설계에 포함되는 요소는 다음과 같습니다
- 실험을 진행할 N개의 군집 설정
- 표본 수 및 실험 기간 정의
- 실험이 반영될 군집에 대한 로직 정의
- KPI정의
- 지표가 동일할 때의 의사결정
첫번째로 실험을 진행할 대상군들을 어떻게 나눌지 정의해야합니다. 말을 좀 더 쉽게 풀자면 즉, 실험군/대조군으로 나눠 AB테스트를 진행할지, ABC 3군집으로 나눠 실험할지에 대해 정의합니다. 이부분은 보통 표본 수 및 실험 기간 정의와 같이 이뤄지는데 실험 대상이 되는 기능이 있으면 그 기능을 사용하는 유저들 모수를 확인합니다. 분석이 가능한 모수라고 판단된다면 이를 AB 혹은 ABC로 군집을 나눠 실험할지 결정하는데 이때 보통은 통계 분석의 최소 표본 수를 맞추기 위해서 ABC테스트를 진행할 땐 실험기간이 좀 더 길게 설정됩니다. 정리하자면 실험 대상이 되는 기능 사용 유저수 파악 → 분석 가능한 모수 파악 → 실험 군집 수 설정 → 실험 기간 설정 으로 진행됩니다.
다음으로 실험이 반영될 군집에 대한 로직정의인데, 위의 사전분석 사례를 그대로 차용하자면 결국엔 설문 기능을 이용하는 유저와 가까운 유저들 순으로 정렬하여 추천해줘야하는데 이 부분에 대한 로직을 개발하게 됩니다. 로직의 경우 백앤드 개발자와 긴밀한 협업을 진행하게 되는데 제가 만든 로직을 실제 비즈니스에 적용하기 위해서는 구현을 위한 작업이 들어가야합니다. 그래서 분석가는 보통 구현할 로직에 대해서 정의를 하고 백앤드 개발자와 의사소통하며 개발한 로직을 구현하는 작업에 서포트를 진행합니다. 그렇게 만들어진 로직은 위에서 정의한 실험 군집에 적용이 됩니다.
마지막으로 실험 KPI를 정의해야 합니다. 실험 KPI는 결국 실험을 성공했는지, 실패했는지에 대한 척도로 나뉘기 때문에 실험설계중 가장 중요한 단계입니다. 제대로 정의한 KPI와 그렇지 못한 KPI는 실험의 성과를 측정하는데 굉장히 중요한 차이를 보이기 때문에 KPI 설정은 굉장히 중요하다고 할 수 있습니다. 예를들어서 리텐션을 개선하려고 했던 실험에 KPI를 리텐션으로 두지 않고 매출이나 추천 비율 등으로 잡게 된다면 올바른 실험 결과를 도출할 수 없게 됩니다. 따라서 실험의 결과를 단락지을 Main KPI를 설정하고 이를 서포트 할 수 있는 Sub KPI들을 설정해서 실험 결과를 분석하게 됩니다. 하지만 이때 모든 군집간 KPI들의 결과가 동일할 때는 보통은 정성적인 요인으로 판단하게 됩니다. 같은 결과일 때 UI,UX적으로 유저경험이 A군집이 좋다 혹은 B군집이 좋다 라는 것으로 최종 선택할 수 있도록 미리 케이스별로 구분지어 정의해놓습니다.
4. 실험 사후분석
실험설계 및 실험 반영까지 끝났다면 설계할 때 정의한 계획대로 진행한 뒤 결과에 대한 사후분석을 진행하게 됩니다. 사후분석은 말그대로 실험이 성공했는지, 실패했는지에 대한 결과를 도출하고 실험을 통해서 획득한 인사이트 및 추가 실험 설계를 진행하게 됩니다. 보통 사후분석의 경우 통계분석을 적절히 활용하는데 이부분은 따로 설명하지 않고 포스팅 해놓은 부분을 참고 부탁드립니다. 링크
실험의 성공/실패는 결국 KPI를 우리가 원하는 값까지 올렸는지, 기존 군집(대조군)보다 높아졌는지를 분석하여 결정을 내린 후 의사결정을 서포트 합니다. 설문 기능을 이용했을 때 추천을 거리가 가까운 순으로 추천해주는 실험의 사후분석은 Main KPI인 설문을 돌리고난 뒤 유저들의 행동력 증가 및 재사용률을 높였는지 확인하는 것으로 진행합니다. 따라서 추천된 유저들의 거리가 가까울수록 행동력과 재사용률이 높아질 것이다라는 가설을 입증할 수 있는 결과를 도출하게 되는데, 실험을 계획한 기간이 지나고 난 뒤 검증을 진행했을 때 실제로 행동력이 증가되었지만, 재사용률은 증가되지 못한 결과를 얻게 되었습니다. 결과적으로 재사용률이 소폭 감소한 것에 비해 행동력이 증가된 폭이 더 컸기 때문에 실험으로 인한 제품 영향성이 긍정적인 효과가 더 높다고 판단하여 전면적용을 진행했습니다.
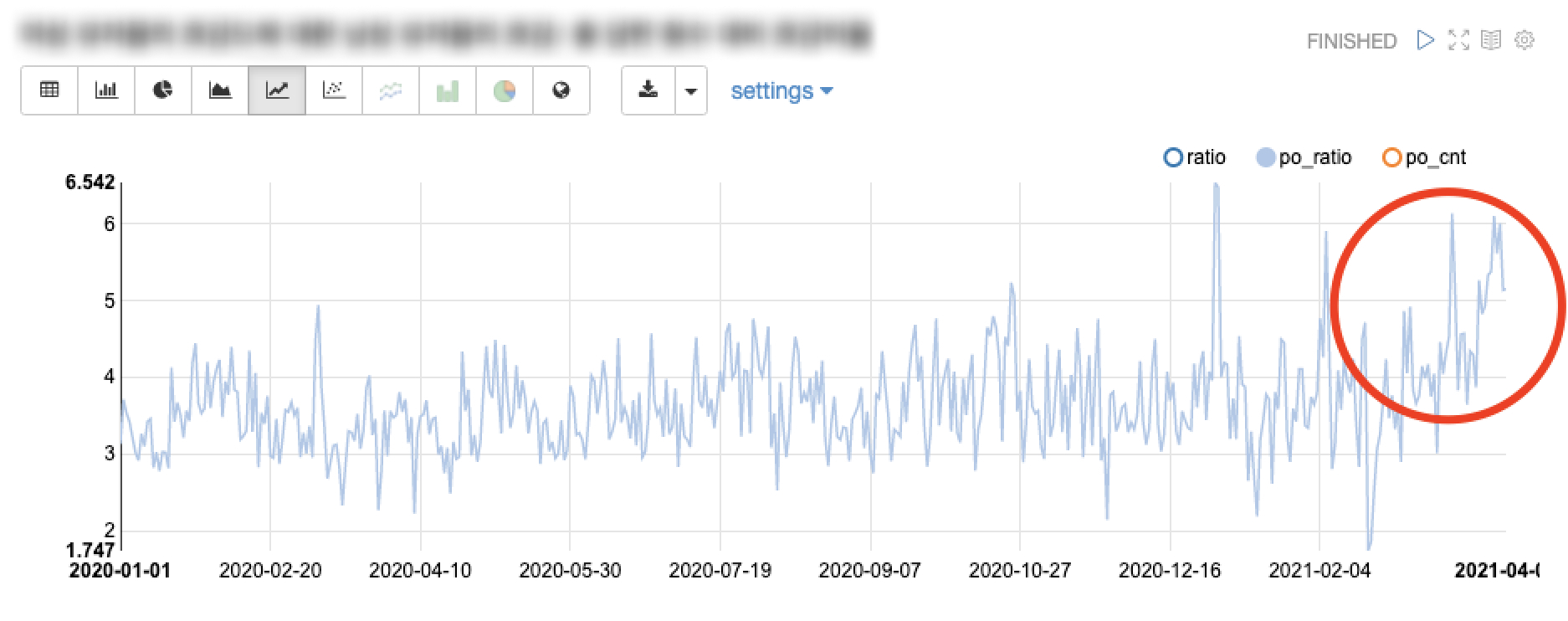
하지만 분석가는 가설처럼 재사용률이 증가되지 못하고 소폭 감소한 것에 대해서도 추가분석이 필요합니다. 재사용률이 감소한 이유는 무엇일까요? 세울 수 있는 가능성이 높은 가설로는 정량적으로 거리가 가까운 순으로 노출시켜주는 로직을 개발할 때 기능 사용과 결과 공유까지 걸리는 소요시간이 증가되었기 때문에 재사용률이 감소했다고 정의할 수 있었습니다. 따라서 해당 실험 이후에 바로 해볼 수 있는 파생 실험은 가까운 거리 순으로 추천해주는 로직에 시간이 오래걸리는 요인을 제거하여 시간과 거리 Factor을 동시에 개선하여 재사용률을 높이는 목표로 추가 실험을 제안할 수 있었습니다.
이처럼 엔라이즈 분석가는 사후분석을 진행할 때 단순히 KPI 달성 여부를 기반으로 실험 성공/실패 에 대한 의사결정 서포트 이외에 분석을 통한 인사이트 수립 및 추가적으로 진행할 수 있는 파생실험 제안까지 진행하고 있습니다.
5. 제품에 활용될 로직 설계
제품 로직 정의는 실험 설계 및 새로운 기능이 개발될 때 데이터에 기반한 기준 정의 및 로직 개발이라고 말씀드릴 수 있습니다. 단순히 특정 기능에 들어갈 로직을 정성적인 요인을 가지로 반영하는 것이 아니라 가장 효율이 좋을 것 같은, 유저 경험이 좋을 것 같은 요소들로 정의하여 데이터에 기반하여 만드는 것을 뜻합니다.
가령, 현재 다양한 채널을 통해서 유저들을 추천해주고 있는데, 특정 채널이 만들어진다고 했을 때 채널 테마에 맞는 사전 데이터를 정의합니다. 거리, 점수, 나이, 선호취미, 특기 등 추천에 필요한 요소를 정의한 뒤 해당 요소들을 조합하여 최적화 추천 로직을 개발합니다. 예를 들어서 “오늘 접속한 동네 친구“라는 채널을 예를 들 수 있습니다. 해당 채널의 경우 처음 만들 때 유저들이 선호하는 요소라고 판단하는 접속 시간과 거리를 조합하여 가장 최근 접속 + 근방의 친구를 추천해줌으로써 유저들의 만족도를 개선한 채널입니다. 해당 채널의 로직은 비교적 최근에 접속한 유저에게 행동력이 좋은점, 거리가 가까울수록 행동력이 좋은점, 채팅 만족도가 좋은 점을 근거로 하여 개발할 수 있었습니다. 그에 따라서 결과도 추천 로직에 대한 만족도가 높다고 정의할 수 있을만한 결과를 도출할 수 있었습니다.
이외에도 “새로가입한 친구“, “지역랭킹“, “보이스톡“ 등 다양한 기능과 채널에 데이터에 기반한 비즈니스 로직을 분석가가 설계하며 로직의 영향성 및 결과에 대해서도 분석을 진행하고 있습니다. 당연하게도 단순히 정성적 요인을 기반으로 만드는 로직보다 데이터에 기반한 로직의 성공률이 압도적으로 높기 때문에 로직을 설계할 때 가장 앞단에 위치하여 진행하고 있습니다.
6. Ad-hoc 분석
Ad-hoc분석은 다양한 팀, 스쿼드에서 들어오는 데이터 추출 및 분석 요청을 포괄하고 있습니다. 스쿼드(팀)에서 특정 데이터를 보고 싶을 때, 업무 관련하여 원하는 분석 내용을 알고 싶을 때 저희 팀에 요청하고 싶습니다. 예를 들어 다음과 같은 요청사항 들이 있습니다.
- 프로모션에 사용할 적정 대상 군집을 산출하고 싶은데 제품을 사용하는 주 연령층이나 성비를 알고 싶습니다.
- 이번 마케팅 캠페인을 통해서 상당히 유저 유입이 많아보이는데 실제로 해당 캠페인이 제품에 미친 영향성을 알고 싶습니다.
- 이번에 00시 ~ 00시까지 서버쪽에 장애가 생겨서 유저들이 불편함을 겪었는데, 불편함으로 생긴 비즈니스적 손해가 어느정도인지 알고 싶습니다
이 외에도 각 팀 및 스쿼드에서 다양한 데이터 및 분석을 요청해주시고 있습니다. 이에 따라서 분석팀은 상시 협업하며 밀접하게 그들의 옆에서 궁금한 부분을 해결해주고, 데이터를 통해 더 나은 의사결정을 할 수 있도록 서포트하고 있습니다.
이처럼 엔라이즈 데이터 분석가가 하고 있는 업무들에 대해서 소개해드렸습니다. 이 글을 봤을 때 어떤 사람은 분석가가 하는 일이 이거밖에 안돼? 또 다른 사람은 이런 일까지 할 수 있어? 등 다양한 생각을 할 수 있을 것입니다. 앞서서 말씀드렸다시피 분석가의 업무는 제약, 제한이 없기 때문에 이 외에도 더 다양한 업무를 진행할 수 있고, 지금 기입되어 있는 일을 더 깊게 개발할 수도 있을 것입니다. 따라서 항상 지니고 있는 생각은 “난 무엇을 할 수 있을까?“ 라는 생각을 지니고 분석가로써 제품의 성장을 도모하고 회사와 나의 발전을 이룰 수 있는 방향의 동일 선상에서 항상 고민하고 있습니다.
저희와 같이 고민할 수 있고, 더 나은 팀을 넘어서 최고의 팀을 만들분을 찾고 있습니다! 간단한 티타임이라도 좋으니 언제라도 minyong.shin@nrise.net로 연락주시면 감사하겠습니다!