
안녕하세요. 위피/콰트의 데이터 분석을 맡고 있는 신민용입니다. 오늘 소개해드릴 내용은 저희 제품팀이 어떻게 실험을 하고 있으며, 어떤 방법론을 활용하여 진행하고 있는지에 대해서 소개해드린 후 앞으로의 방향도 짧게 다뤄보겠습니다. 본격적인 소개에 앞서 저희의 전체 실험 플로우를 나타내는 그래프입니다.
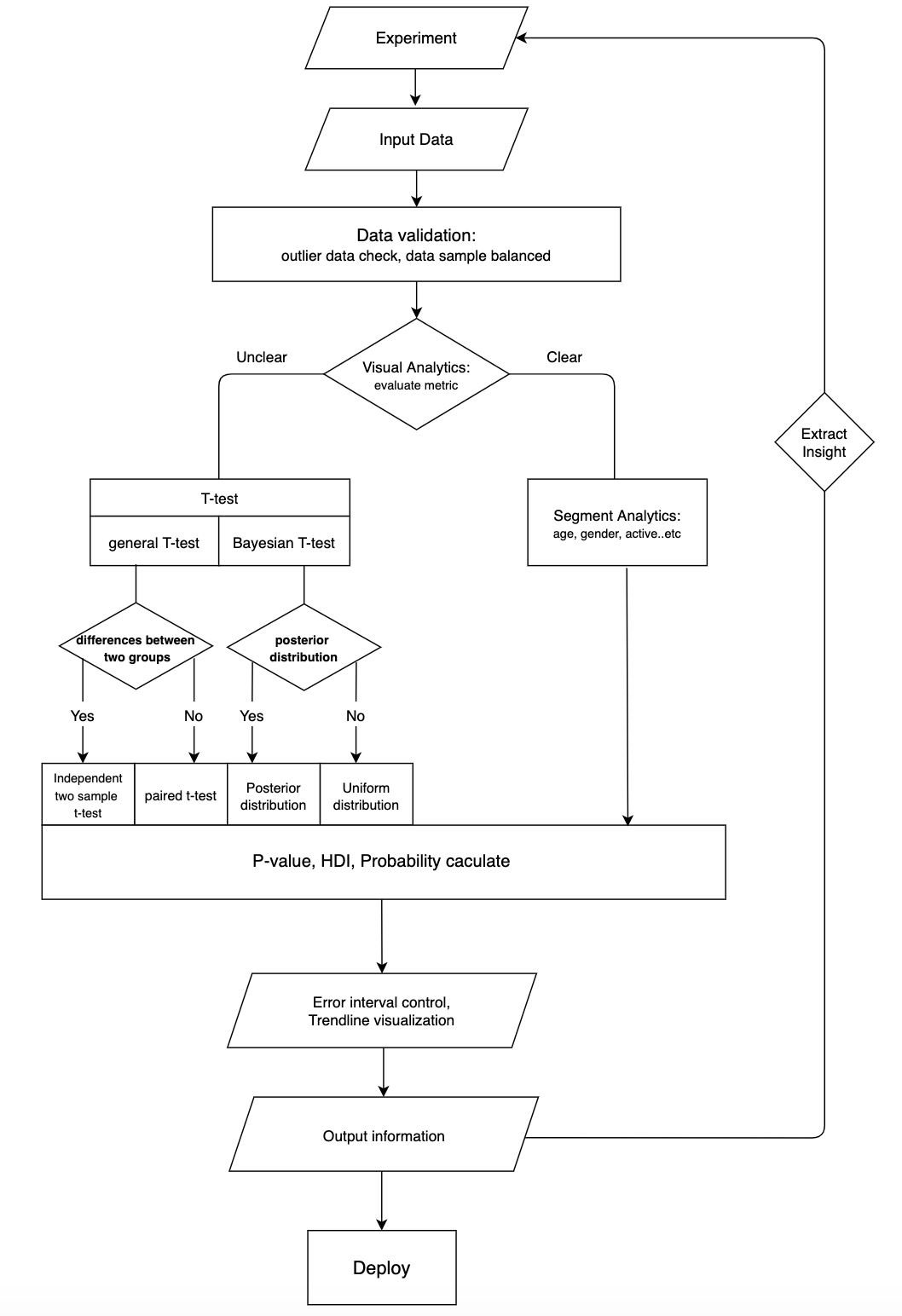
전체 실험 플로우
사전분석
실험을 진행하기전에 해당 실험을 통해서 개선하고자 하는 KPI, 가설을 수립하게 됩니다. 그래서 저희는 ad-hoc 분석을 통해 사전적으로 현행지표 파악 및 특정 로직 변경 및 기능 개발을 통한 지표 개선에 대한 가설을 수립합니다. ad-hoc분석을 하는 이유는 실험으로 인해 영향을 받을 수 있는 지표 파악과 실험의 정확도를 향상시킬 수 있기 때문입니다.

여기서 질문이 있을 수 있습니다. “모든 실험을 사전 분석 할 수 있나?“에 대한 질문에 “아니오"라고 할 수 있습니다. 저희가 지금껏 다루지 않았던 지표개발이나 기획-개발-실험의 전체 플로우에서 신속하게 개선사항을 확인해보기 위해서는 모든 실험에 사전분석을 하지 않고 있습니다. 실제로 저희 제품팀은 사전분석이 적극적으로 필요하지 않는 실험에 대해서는 실험을 빠르게 진행하여 결과 확인 후 추가 실험이라는 사이클로 진행되고 있습니다. 말 그대로 사전분석이기 때문에 결과를 어느정도 예측할 수 있지만 유저의 행동을 100% 예측할 수 없기 때문에 오히려 신속하게 실험을 도입하고 “N차 실험” 을 통해 지표를 빠르게 개선하고 있습니다.
유저군 샘플링 및 실험 진행
사전분석-기획-개발이 진행된 이후 실험에 필요한 유저 군집을 샘플링해야합니다.
유저 샘플링에 관련해서는 회사마다 다르겠지만 저희의 경우는 서버팀과 협업하여 저희가 실험에 필요한 유저 세그먼트 정의 후 내부 알고리즘을 통해 실험군, 대조군으로 분할하여 실험을 진행하고 있습니다.
실험 진행은 클라이언트 업데이트, 서버 로직 변경을 통해서 이루어지고 있는데 이부분에서 중요한 부분이 “데이터 정합성 체크"입니다. 실험이 반영이 되면 앱을 사용하는 유저들의 UI 혹은 기능들이 바뀌게 되고 이에 따라 유저들의 바뀐 행동 데이터가 쌓이게 됩니다. 그렇기 때문에 실험이 반영되면서 기능이 제대로 반영이 되었는지, 원하는 조건에 맞게 실험이 세팅이 되었는지를 체크하는 과정을 데이터를 통해 검증하는 부분이 실험 진행에 있어 중요한 부분이라고 할 수 있습니다. 아래의 두 예시를 봐도 충분히 이해가실 것이라 생각합니다.
- “반영된지 5일 후에 유저 세그먼트가 잘못 할당되었다는 것을 확인한 분석가 A”
- “반영된지 1시간 후 데이터를 확인하여 로직에 맞게 추천이 되지 않았다는 것을 확인한 분석가 B”
그렇기 때문에 실험은 실험 반영 후 클라이언트 업데이트, 서버 로직 변경 분류에 따라 일정을 추산하고 평균적으로 7+@의 기간을 두고 “반영 → 데이터 검증 → 분석 → 결과도출"의 사이클을 돌리고 있습니다. 또한 기획 및 상황에 따라 “전후 테스트”, “A/B 테스트“를 두고 결정하기도 하는데 대부분 A/B 테스트를 통해 가설을 검증하며, 때때로 기능 전면적용 후 전후분석을 통해서 결과를 분석하고 있습니다.
실험 결과 분석
저희는 결과를 분석할 때 featrue selection기법중 하나인 Forward Stepwise 방식으로 실험을 분석하고 있습니다. 이때 Forward Stepwise의 순서에 들어가는 feature는 “소요 시간”, “Advanced statistic analysis"로 두고 있습니다. 그렇기 때문에 “소요시간"이 빠를수록, “고급 통계 분석이 아닌 단순화된 분석"부터 단계를 밟아가며 진행하는 것을 뜻합니다.
저희 분석팀은 Main KPI와 Sub KPI들을 산정하고 분석을 진행하며 하나의 실험에 대해서 보통 10개 이상의 Metric 을 통해서 종합적인 결론을 도출합니다.
위처럼 저희가 분석을 진행할 때 사용하는 방법론은 3가지이며 다음의 순서는 Forward Stepwise 순서입니다.
- 시각화 분석
- 오차범위 제어 및 추세분석
- Bayesian T-test, T-test
시각화 분석의 경우 가장 간단한 방법으로 보통은 해당 단계에서 결과를 추출할 수 있습니다. 비교적 짧은 시간이 소요되고 고급 통계 분석이 필요하지 않은 단계이지만 결과를 분석하는데 있어서 가장 직관적인 방법론이기 때문에 단계중 가장 첫 단계로 사용하고 있습니다. 매 실험마다 10개 이상의 지표를 활용하여 분석하기 때문에 단순히 Python, R을 통해서 분석하기에 시간이 다소 소요되는 부분이 있습니다. 그래서 저희는 zeppelin을 통해 (대시보드:실험=1:1)로 관리를 하면서 실험 지표를 트래킹하고 있습니다. BI같은 경우 회사마다 Tableau, Data studio, redash, zeppelin 등 다양하게 활용을 하고 있지만, 저희도 여러 BI툴을 사용해본 결과 zeppelin이 가장 저희 팀의 핏과 잘 맞는다고 판단하여 결정하게 되었습니다.
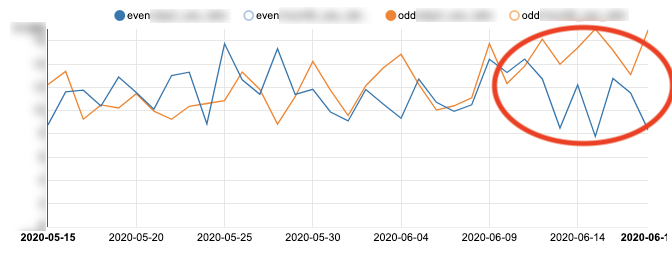
위는 저희가 실제로 실험을 하면서 보았던 지표중 Main KPI의 추세를 나타낸 그래프인데 실제로 시각화 분석을 통해 특정 실험에 대한 결과 차이를 실험군과 대조군을 비교하여 설명할 수 있게됩니다. 위의 그래프와 달리 Main KPI가 오차범위 내일 때는 빠르게 Sub KPI를 분석하여 차선지표를 통해 실험을 검증합니다. 그렇기 때문에 시각화 분석은 가장 빠르고, 쉽게 실험 분석을 통해 결과를 도출할 수 있는 장점이 있습니다. 하지만 때론 명확한 결론을 내릴 수 없는 지표추이를 보이는 상황들이 있습니다. 그럴 때는 무작정 대략적인 값과 시각화 결과를 보고 결론을 내린다면 신뢰성이 없어지기 때문에 저희는 다음 방안을 통해 결론을 내고 있습니다.
오차범위 제어 및 추세분석는 시각화 분석을 통해 지표를 해석하기 애매한 상황에서 몇가지 기법을 통해서 의사결정의 신속성을 높이기 위해 도입하게 되었습니다. 각 지표별 오차를 계산한 뒤 smoothline을 통해서 추세선을 시각화하고 그 값을 기준으로 오차범위를 산정합니다.
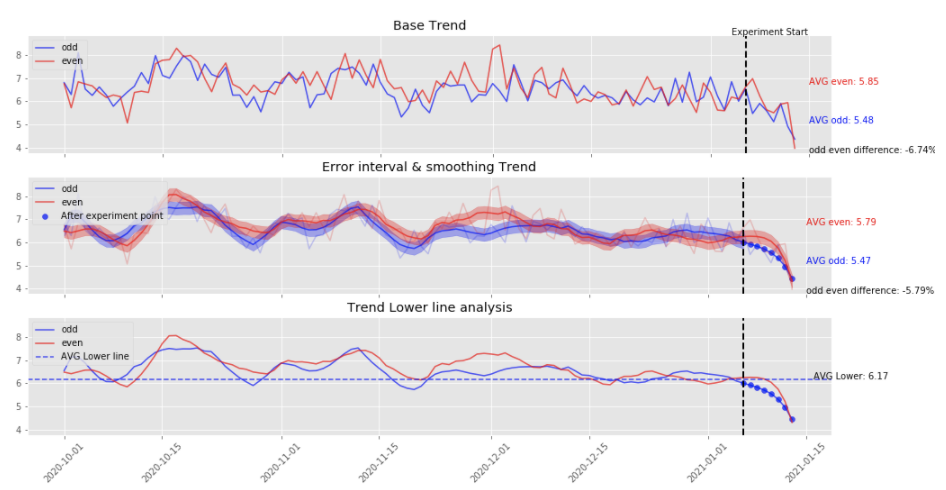
위의 그래프는 실제로 저희가 실험했을 당시의 지표를 분석한 결과입니다. 위처럼 기존 지표 트렌드가 시각화 분석에만 의존했을 때 애매한 부분을 아래의 자료들을 통해서 한눈에 확인할 수 있습니다. 그래서 기존 지표 트렌드, 추세선과 오차범위, 추세선의 데이터를 하나의 차원에서 나타냅니다.
지금은 검증할 데이터, 지표, 날짜만 기입하면 자동으로 결과를 리포팅할 수 있게끔 관리하고 있습니다. 따라서 오차범위를 넘어서는 상태로 비교할 군집의 지표가 계속 낮은지 혹은 높은지 확인하며, 실험기간동안 두 집단의 지표 트렌드가 어떤 추세를 보이는지 한눈에 확인할 수 있으며, 지표간의 차이를 평균적으로 확인할 수 있습니다. 해당 방법을 활용했을 때 시각화 분석보다는 데이터를 추출하는 시간과 지표를 확인하는 시간이 어느정도 소요되기 때문에 시간적인 부분에서는 활용도가 낮지만 두 집단을 좀 더 명확하게 구분하여 실험 결과를 도출할 수 있다는 장점이 있습니다. 마지막으로 저희가 통계적 집단 비교 방법론을 활용하는 부분을 말씀드리겠습니다.
저희는 Bayesian T-test, T-test를 활용하여 집단 비교 분석을 진행하고 있습니다. 지금은 데이터 분포, 가정에 따라 T-test도 간혹 이용하긴 하지만 대부분 Bayesian test를 통해서 비교분석을 진행하고 있습니다. 저희가 A/B Test를 진행할 때 Bayesian과 일반적인 T-test를 어떻게 도입해서 사용중인지는 추후에 포스팅을 하겠습니다. 현재 전후 분석을 진행할 때는 대응표본T검정을 활용하다가 현재는 전후분석 또한 Bayesian을 활용하여 분석하고 있으며, 동기간의 두 집단 분석을 진행할 때는 상황에 따라 독립표본T검정, Bayesian을 활용하고 있습니다. 간략하게 Bayesian을 활용한 실험분석 방법론에 대해서 설명드리자면, 저희가 확인할 지표들의 사전분포(Posterior distribution)를 알고 있다면 이에 따라 활용할 분포를 정의합니다. 하지만 실제로 분석을 진행하다보면 사전분포를 모르는 경우가 많기 때문에 균등분포(Uniform)를 가정하고 사전분포로써 균등분포를 활용하고 있습니다.
아까 위에서 보이는 것처럼 지표 트렌드의 명확성이 뒷받침해 있지 않은 상태에서 Bayesian을 활용해서 분석을 진행했을 때 지표의 차이를 조건부 확률에 기반해서 도출할 수 있게됩니다.
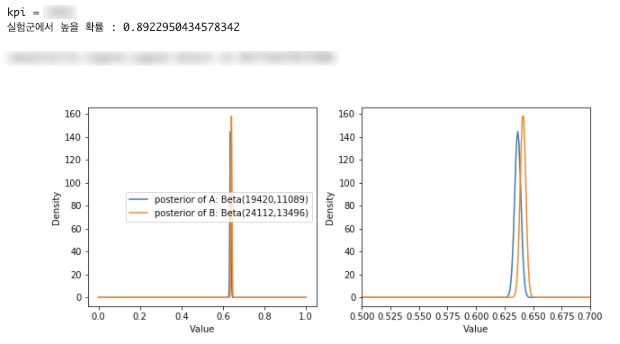
그리고 Bayesian은 일반 T검정과 다르게 p-value(유의확률)를 사용하지 않고 HDI(Higest Density Interval)를 활용하여 두 집단간의 우의를 확률로써 검증합니다. 그렇기 때문에 p-value로 해석할 수 있는 A집단과 B집단간의 차이가 없다라는 귀무가설을 기각하고, 가설에 대한 유의성만을 검증하는 것보다 위 사진처럼 두 집단에 대한 차이를 확률로써 검증하기 때문에 더 직관적으로 분석할 수 있게 됩니다.
이처럼 현재는 실험에 다양한 방법론을 도입하고 있으며, “더 신속하고”, “더 정확한” 분석결과를 도출하기 위해서 지속적으로 추가적인 방법론에 대해서 스터디하고 구현하고 있습니다. 또한 추후에는 실험 자체를 플랫폼화하여 관리하고, 분석하는 것을 목표로 두고 있습니다.
실험 결과 분석에 따른 결정
지금까지 “실험 계획 → 반영 → 분석"에 대해서 살펴봤다면, 마지막으로 분석한 결과를 어떻게 다루는지에 대해서 설명드리고자합니다.
팀, 조직마다 다르겠지만 저희 같은 경우는 “실험 계획 → 반영 → 분석 → PM과 분석결과 공유 → 결과 전면적용 혹은 롤백"의 사이클을 따르면서 추가적인 작업들을 지속하고 있습니다. 저희는 작은 실험을 진행하더라도 분석결과에 따른 전면적용 혹은 롤백에서 멈추지 않고, 해당 분석에서 도출한 인사이트를 활용하여 추가적인 실험에 대해서 지속적으로 논의하고 있습니다. 위피 내부의 기능인 지역랭킹 기능의 상단 배너 UI에 자기 사진을 넣는 것과 이모지를 넣는 것에 대한 실험을 예로 들어보겠습니다.
- 상단 배너 자기사진(실험군)

- 상단 배너 이모지(대조군)

두가지 실험의 결과는 자기 사진을 넣었을 때 배너를 클릭하는 비율, 랭킹을 확인하는 비율이 증가했습니다. 이 때 같은 결과를 보고 접근하는 방법이 다를 수 있는데 아래의 예시가 있습니다.
- “실험군으로 바로 전면적용을 요청드립니다.”
- “실험군으로 바로 전면적용을 요청드립니다. 그런데 자신의 얼굴을 노출시켰을 때 유저들의 반응률이 더 개선이 되어서 자기 얼굴이라는 팩터가 유저 행동에 영향을 주는 키라고 생각하는데 이걸 좀 응용해보면 좋을 것 같습니다”
두가지 결정은 같은듯 보이지만 굉장히 다른 것을 알 수 있습니다. 결론적으로 해당 지역랭킹의 푸시 썸네일에 자기 사진을 넣어서 보내는 실험을 요청드렸고, 그 결과 푸시 클릭률을 평균적으로 약 24%를 개선하게 되었습니다. 그렇기 때문에 분석한 결과를 통해서 인사이트를 전달 및 추가 실험을 제안할 수 있는 것과 단순히 결과 리포팅에 멈추는 것은 명확히 다를 것이라 생각됩니다.
이처럼 저희 조직은 분석한 결과에서 멈추고 단순히 반영할지 롤백할지에 대해서 결정하는 것이 아니라 분석한 인사이트를 가지고 파생할 수 있는 방안들을 같이 생각하여 추가적인 실험으로 반영하고 있습니다.
따라서 저희는 기본 실험이든 실험 후 인사이트를 통해 파생한 실험이든 성공/실패에 의미를 두지 않습니다. 성공이든 실패든 그 안에서 어떤 요인 때문에 성공했는지, 실패했는지를 명확하게 분석하여 그 과정 자체에 의미를 두고 지속적인 실험을 진행하고 있습니다. 엔라이즈에서는 저희와 같이 실험 방식을 개선할 능력 있는 분석가분을 찾고 있습니다. 저희 팀에 관해 궁금한 점이나 관심이 있으신 분들께서는 minyong.shin@nrise.net 으로 연락 부탁드리겠습니다!